Integrar API gitlab a confluence.

Cómo integrar Confluence con GitLab.
En este manual, aprenderemos a integrar dos tecnologías a través de sus API utilizando Python. El laboratorio que vamos a realizar muestra cómo obtener los datos de un README.md de algún proyecto de GitLab y subir ese contenido a Confluence en un espacio y página previamente configurado con el mismo formato de origen.
Configuración.
Crear y configurar el laboratorio.
Requerimientos.
- Cuenta en GitLab.
- Cuenta en Confluence.
- Python.
GitLab.
- Crear una cuenta en GitLab.
- Creamos un proyecto.
- Generamos un token para el proyecto.
Con Python, vamos a configurar una conexión a la API de GitLab y ver qué opciones tenemos para conectar y ver el contenido de un proyecto.
Requerimientos.
- Librería de GitLab:
pip install python-gitlab. - Librería Markdown:
pip install markdown2. - Nombre de usuario.
- ID del proyecto.
- Token.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import gitlab
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
print(project)
#Respuesta.
<class 'gitlab.v4.objects.projects.Project'>
Con esta conexión, podemos comprobar la configuración de GitLab. Pero ahora vamos a obtener información más detallada del proyecto, como el ID, la hora y el correo electrónico.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import gitlab
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
# Obtener el último commit
commit = project.commits.list()[0]
print(f"ID:{commit.id} \nFECHA:{commit.authored_date} \nEMAIL:{commit.committer_email}")
#Respuesta
ID:87a993b0379ff87e0b1832684d36c077ff528075
FECHA:2023-04-19T13:36:37.000+00:00
EMAIL:test@gmail.com
Puedes ver mas opciones llamando solo la variable commit
print(commit)
Vemos que podemos obtener información más detallada de los commits de un proyecto, pero el objetivo de este laboratorio es poder obtener la información que contiene el README.md. Vamos a seguir desarrollando el script para lograrlo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import gitlab
import markdown2
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
# Obtener el último commit
commit = project.commits.list()[0]
# Obtiene el árbol de archivos del proyecto
tree = project.repository_tree()
# Itera sobre el árbol de archivos y muestra el contenido de cada archivo
for file in tree:
# Verifica si el archivo es un archivo README.md
if file["name"].lower() == "readme.md":
# Obtiene el contenido del archivo
file_content = project.files.get(file["path"], ref=commit.id).decode()
# Imprime el contenido del archivo
html = markdown2.markdown(file_content)
print(html)
#Respuesta
<h1>CONTENIDO DEL README</h1>
<p>Este readme.md es un ejemplo.</p>
<h2>Subtítulo</h2>
<h3>Notas</h3>
En este punto, ya tenemos acceso al contenido del README.md. Ahora vamos a configurar el entorno de Confluence para subir la información que obtuvimos de GitLab.
Confluence
- Crear una cuenta en Confluence.
- Crear un espacio.
- Crear una página.
- Generar un token.
Como hicimos anteriormente con GitLab, vamos a crear una conexión para hacer pruebas y ver qué opciones tenemos.
Requerimientos:
- Librería:
pip install atlassian-python-api. - Librería Markdown:
pip install markdown2. - Nombre de usuario.
- Token.
- Nombre del espacio.
- Nombre de la página.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from atlassian import Confluence
url = 'https://TEST.atlassian.net'
username = 'TU-USUARIO'
token = 'TU-TOKEN'
# Conectar Confluence
confluence = Confluence(url=url, username=username, password=token)
# Selecciones su espacio y titulo de la pagina
space_key = 'TU-ESPACIO'
page_title = 'TU-PAGINA'
# Verificar que existe la pagina
existing_page = confluence.get_page_by_title(space=space_key, title=page_title)
#Respuesta.
print(existing_page)
>'id': '6545875234', 'type': 'page', 'status': 'current'
>Error al conectarse a Confluence. #Comprueba los datos de las variables url, username, token
Si recibimos una respuesta exitosa con un status code 200, ya podemos realizar pruebas y subir contenido a Confluence. Vamos a probar subiendo un poco de texto a la página que creamos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from atlassian import Confluence
url = 'https://TEST.atlassian.net'
username = 'TU-USUARIO'
token = 'TU-TOKEN'
# Conectar Confluence
confluence = Confluence(url=url, username=username, password=token)
# Selecciones su espacio y titulo de la pagina
space_key = 'TU-ESPACIO'
page_title = 'TU-PAGINA'
# Verificar que existe la pagina
existing_page = confluence.get_page_by_title(space=space_key, title=page_title)
page_id = existing_page['id']
current_content = confluence.get_page_by_id(page_id=page_id, expand='body.storage')['body']['storage']['value']
#Contenido que vamos a agregar.
add_text = "CONTENIDO DE PRUEBA"
#Actualizamos la pagina con el contenido nuevo.
updated_content = f"{add_text}"
confluence.update_page(page_id=page_id, title=page_title, body=updated_content)
Verificamos en Confluence el contenido que agregamos a la página.
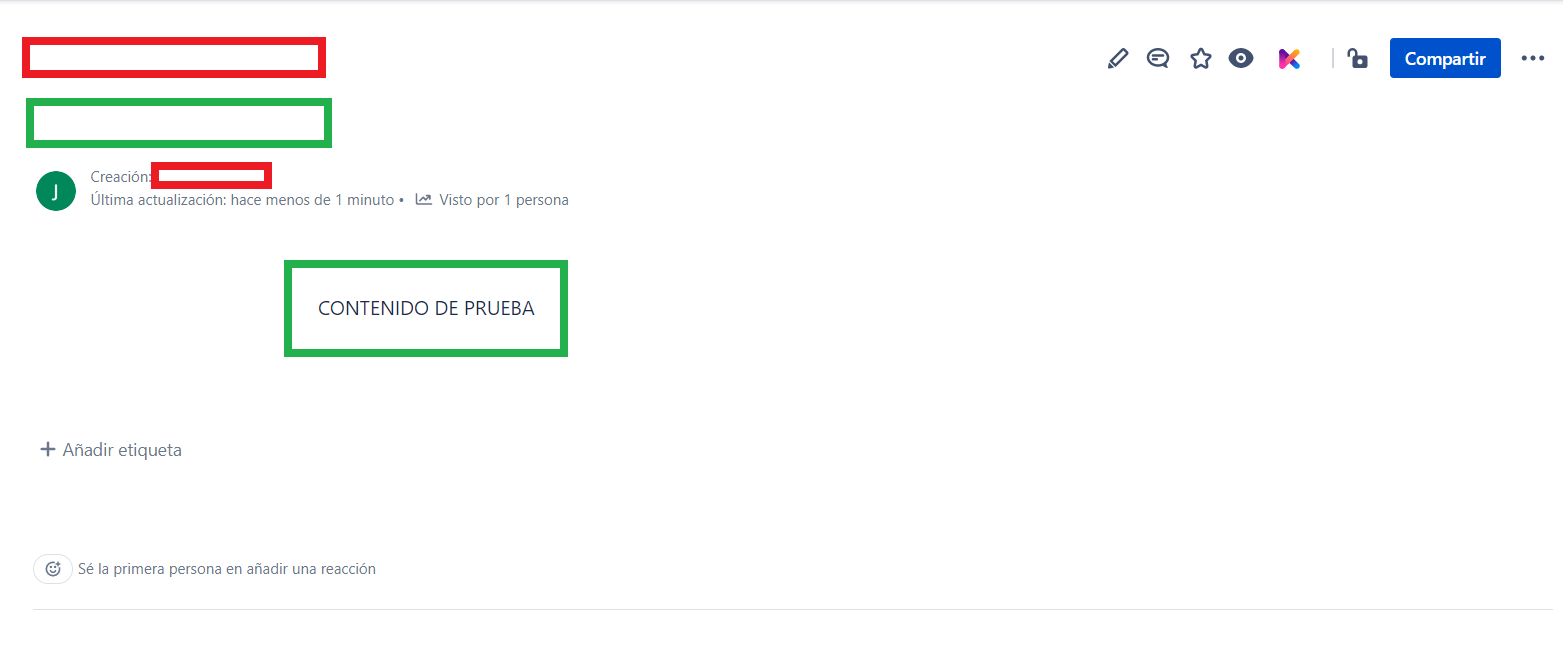
En este punto, ya tenemos una forma de subir contenido a Confluence, pero tenemos un problema: cada vez que subimos contenido, eliminamos el anterior. Esto es válido, pero el objetivo de este laboratorio es almacenar un historial de los cambios del proyecto de GitLab.
Integración de GitLab con Confluence
Vamos a cambiar el contenido que subimos a Confluence por información obtenida de GitLab. Comencemos subiendo los datos de un commit, como el ID, el correo electrónico y la fecha.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import gitlab
import markdown2
from datetime import datetime
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
# Obtener el último commit
commit = project.commits.list()[0]
##############################################################################################
# Convertir a markdown
date = datetime.now()
new_md = f"\n --- \n# Informe fecha {date.date()} \n**Hora** *{date.strftime('%H:%M')}* \n**ID**: *{commit.id}* \n**Mail**: *{commit.committer_email}* \n**Mensaje**: *{commit.title}* \n ---"
new_html = markdown2.markdown(new_md)
##############################################################################################
from atlassian import Confluence
url = 'https://TEST.atlassian.net'
username = 'TU-USUARIO'
token = 'TU-TOKEN'
# Conectar Confluence
confluence = Confluence(url=url, username=username, password=token)
# Selecciones su espacio y titulo de la pagina
space_key = 'TU-ESPACIO'
page_title = 'TU-PAGINA'
# Verificar que existe la pagina
existing_page = confluence.get_page_by_title(space=space_key, title=page_title)
page_id = existing_page['id']
current_content = confluence.get_page_by_id(page_id=page_id, expand='body.storage')['body']['storage']['value']
#Actualizamos la pagina con el contenido nuevo.
updated_content = f"{current_content}\n{new_html}\"
confluence.update_page(page_id=page_id, title=page_title, body=updated_content)
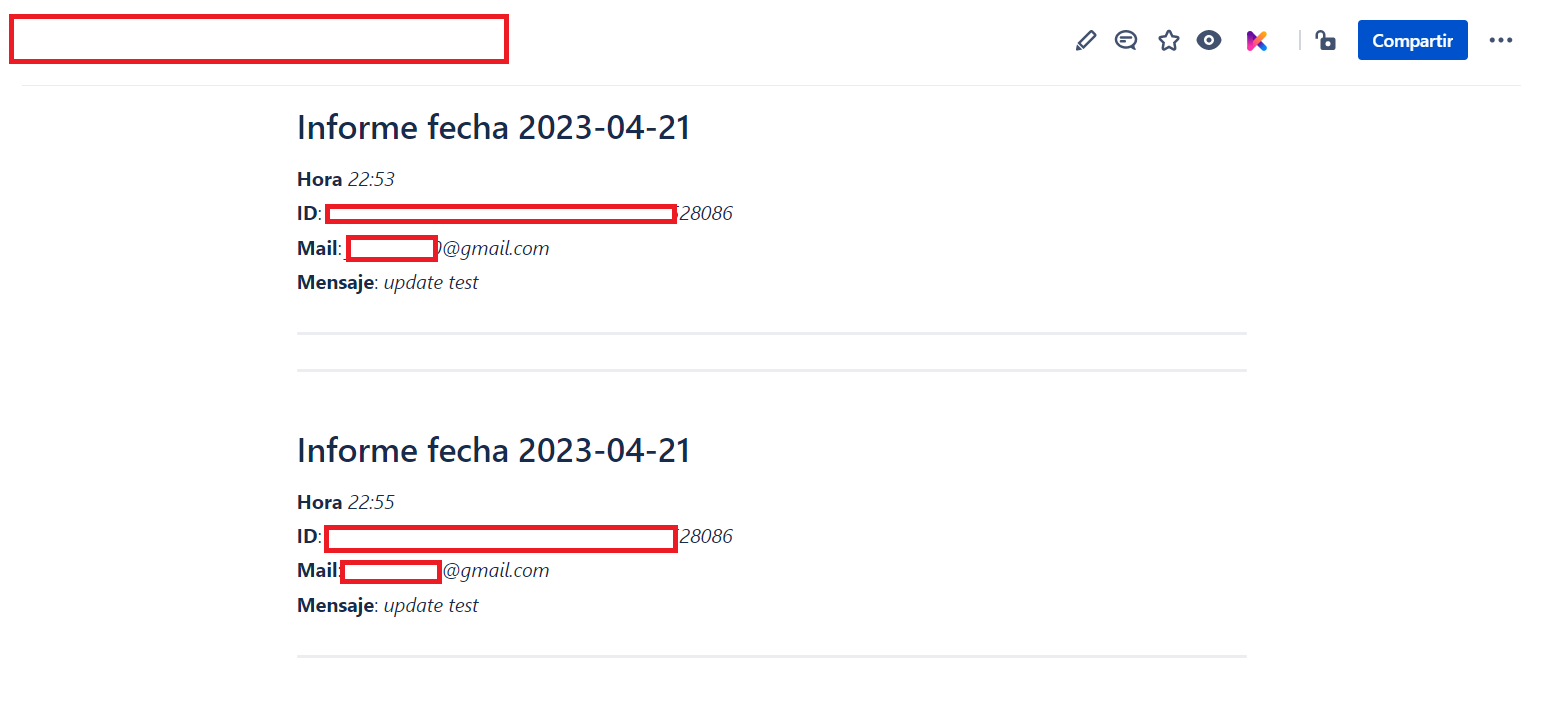
Se puede evitar usar la libreria datetime y usar
commit.authored_datepara obtener la fecha y la hora.
Como se ve en la imagen, hemos hecho dos llamadas a Gitlab y subido las respuestas a Confluence con formato Markdown. El script está cumpliendo el objetivo de integrar las API de Confluence y Gitlab.
Ahora vamos a ejecutar una prueba más, agregando el contenido del archivo README.md a la llamada anterior.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
import gitlab
import markdown2
from datetime import datetime
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
# Obtener el último commit
commit = project.commits.list()[0]
# Obtiene el árbol de archivos del proyecto
tree = project.repository_tree()
# Itera sobre el árbol de archivos y muestra el contenido de cada archivo
for file in tree:
# Verifica si el archivo es un archivo README.md
if file["name"].lower() == "readme.md":
# Obtiene el contenido del archivo
file_content = project.files.get(file["path"], ref=commit.id).decode()
# Imprime el contenido del archivo
html = markdown2.markdown(file_content)
##############################################################################################
# Convertir a markdown
date = datetime.now()
new_md = f"\n --- \n# Informe fecha {date.date()} \n**Hora** *{date.strftime('%H:%M')}* \n**ID**: *{commit.id}* \n**Mail**: *{commit.committer_email}* \n**Mensaje**: *{commit.title}* \n ---"
new_html = markdown2.markdown(new_md)
##############################################################################################
from atlassian import Confluence
url = 'https://TEST.atlassian.net'
username = 'TU-USUARIO'
token = 'TU-TOKEN'
# Conectar Confluence
confluence = Confluence(url=url, username=username, password=token)
# Selecciones su espacio y titulo de la pagina
space_key = 'TU-ESPACIO'
page_title = 'TU-PAGINA'
# Verificar que existe la pagina
existing_page = confluence.get_page_by_title(space=space_key, title=page_title)
page_id = existing_page['id']
current_content = confluence.get_page_by_id(page_id=page_id, expand='body.storage')['body']['storage']['value']
#Actualizamos la pagina con el contenido nuevo.
updated_content = f"{current_content}\n{new_html}\n{html}"
confluence.update_page(page_id=page_id, title=page_title, body=updated_content)
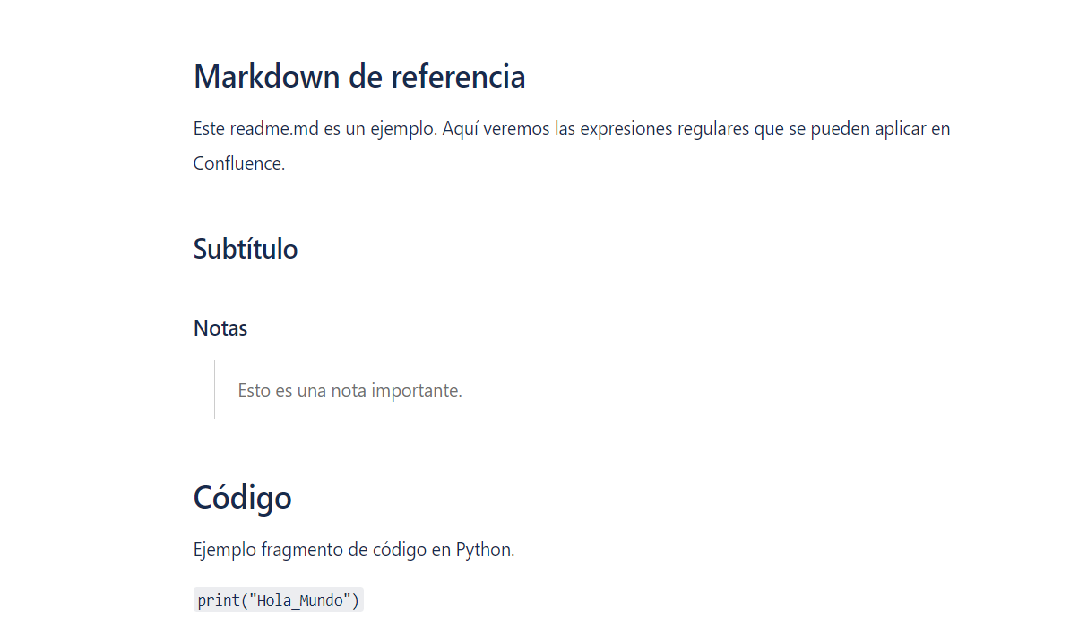
Confirmamos que el contenido se ha subido correctamente a Confluence. De esta forma, podemos crear un historial muy completo en Confluence cada vez que se modifique un proyecto en GitLab.
Una cuestión a tener en cuenta es que el script se tiene que ejecutar de manera manual. Esto puede ser un problema si en algún momento realiza un cambio en GitLab y no recuerda ejecutar el script para guardar los cambios en Confluence. Se puede automatizar el script con una tarea programada en Windows o Linux. Esto guardaría datos, se hagan o no cambios en GitLab. Sin embargo, esto no tiene sentido si lo que queremos es guardar información solo cuando se realicen cambios en los proyectos. Así que vamos a automatizar todo esto usando webhooks y Flask.
Automatizar el script.
Configurar el webhook en GitLab.
Para configurar el webhook necesitamos Ngrok, una herramienta de uso gratuito que nos permite exponer nuestro entorno local a la web. Simplemente ejecutamos ngrok.exe http 5000 y copiamos la URL que se genera en GitLab.
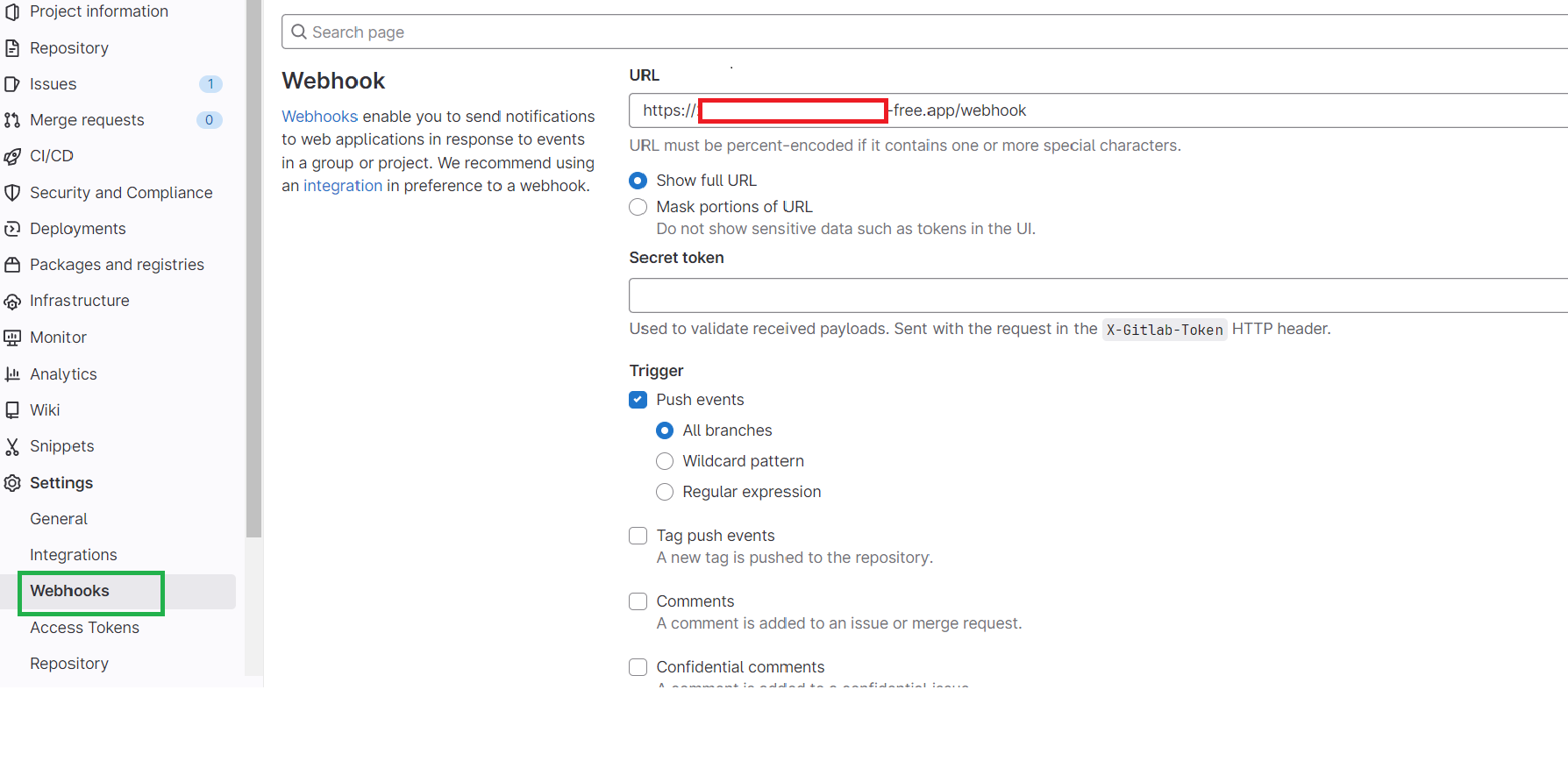
Ahora vamos a integrar Flask al script para crear un servidor web y escuchar los eventos del webhook de GitLab.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
from flask import Flask, request
from atlassian import Confluence
import gitlab
import markdown2
from datetime import datetime
app = Flask(__name__)
@app.route('/webhook', methods=['POST'])
def webhook():
#Conexion a gitlab
gl = gitlab.Gitlab('https://gitlab.com', private_token='TU-TOKEN')
# Obtener datos del proyecto.
project_id = 'PROYECTO-ID'
project = gl.projects.get(project_id)
# Obtener el último commit
commit = project.commits.list()[0]
# Obtiene el árbol de archivos del proyecto
tree = project.repository_tree()
# Itera sobre el árbol de archivos y muestra el contenido de cada archivo
for file in tree:
# Verifica si el archivo es un archivo README.md
if file["name"].lower() == "readme.md":
# Obtiene el contenido del archivo
file_content = project.files.get(file["path"], ref=commit.id).decode()
# Imprime el contenido del archivo
html = markdown2.markdown(file_content)
##############################################################################################
# Convertir a markdown
date = datetime.now()
new_md = f"\n --- \n# Informe fecha {date.date()} \n**Hora** *{date.strftime('%H:%M')}* \n**ID**: *{commit.id}* \n**Mail**: *{commit.committer_email}* \n**Mensaje**: *{commit.title}* \n ---"
new_html = markdown2.markdown(new_md)
##############################################################################################
from atlassian import Confluence
url = 'https://TEST.atlassian.net'
username = 'TU-USUARIO'
token = 'TU-TOKEN'
# Conectar Confluence
confluence = Confluence(url=url, username=username, password=token)
# Selecciones su espacio y titulo de la pagina
space_key = 'TU-ESPACIO'
page_title = 'TU-PAGINA'
# Verificar que existe la pagina
existing_page = confluence.get_page_by_title(space=space_key, title=page_title)
page_id = existing_page['id']
current_content = confluence.get_page_by_id(page_id=page_id, expand='body.storage')['body']['storage']['value']
#Actualizamos la pagina con el contenido nuevo.
updated_content = f"{current_content}\n{new_html}\n{html}"
confluence.update_page(page_id=page_id, title=page_title, body=updated_content)
return 'Webhook received and processed'
if __name__ == '__main__':
app.run()
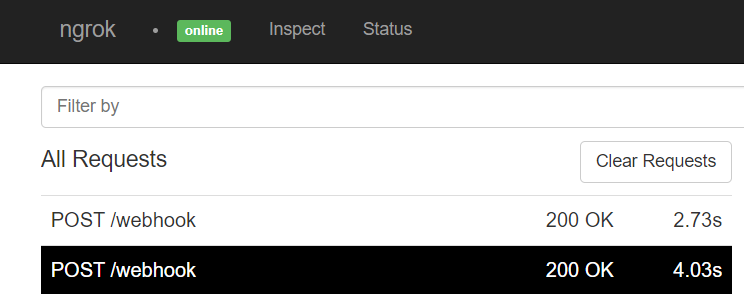
Confirmamos que cada vez que se genera un evento en el proyecto de GitLab, se envía una carga HTTP al servidor que creamos mediante Flask y, a continuación, el contenido se sube a Confluence.